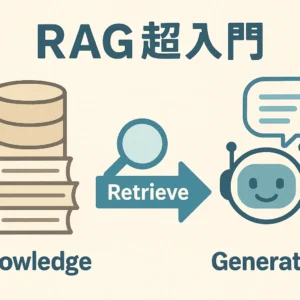
近年、大規模言語モデル(LLM)の進化は目覚ましく、その応用範囲は日々拡大しています。特に、LLMが外部の知識ソースを参照して回答精度を向上させる「RAG(Retrieval Augmented
Generation)」は、多くの場面で活用されています。しかし、そのRAGにも進化の波が訪れています。それが「Agentic RAG」です。
本コラムでは、この新たな概念であるAgentic RAGとは何か、そして従来のRAGと何が違うのかを分かりやすく解説します。
Agentic RAGとは? – 「自律的」に進化した検索拡張
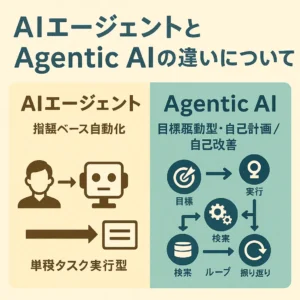
Agentic RAGとは、一言で言えば、LLMに「エージェント」としての役割を持たせることで、より自律的かつ高度な情報検索と回答生成を実現するRAGの進化形です。
従来のRAGは、ユーザーからの質問に対し、関連性の高い情報を外部データベースから検索し、その情報を基にLLMが回答を生成するという、比較的シンプルなプロセスでした。
一方、Agentic RAGでは、LLMが単に情報を受け取るだけでなく、自ら思考し、計画を立て、必要な情報を能動的に収集・分析し、場合によっては複数のツールを使い分けながら、より複雑な質問やタスクに対応します。あたかも、優秀なリサーチャーやアシスタントのように振る舞うのです。
Agentic RAGに期待される主な能力
タスクの分解
複雑な質問を複数のサブタスクに分解し、それぞれに必要な情報を収集する。
戦略的な検索
最初の検索結果が不十分な場合、検索クエリを改善したり、異なる情報源を探したりするなど、検索プロセスを調整する。
複数ソースの統合
複数の情報源から得られた情報を統合し、矛盾点を解消したり、より包括的な回答を生成したりする。
ツールの利用
検索だけでなく、計算、コード実行、API連携など、必要に応じて様々なツールを使いこなす。
対話的な改善
ユーザーとの対話を通じて、質問の意図をより深く理解し、回答の質を向上させる。
これらの能力により、Agentic RAGは、従来のRAGでは難しかった、より深い分析や洞察、複雑な問題解決への貢献が期待されています。
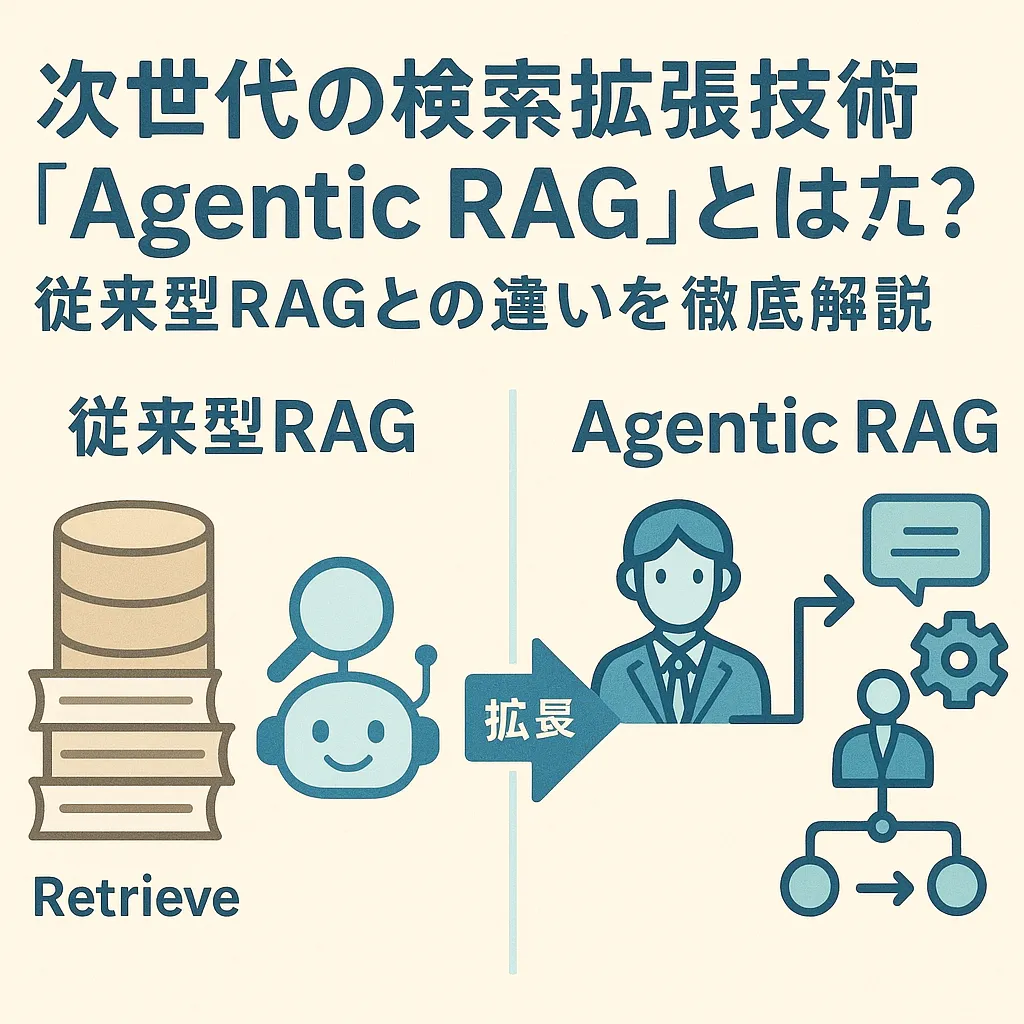
従来のRAGとの違いは? – 「受動的」から「能動的」へ
Agentic RAGと従来のRAGの最も大きな違いは、その「自律性」と「能動性」にあります。
| 特徴 | 従来のRAG | Agentic RAG |
|---|---|---|
| 役割 | 情報検索と回答生成の受動的な実行 | 自律的な思考、計画、情報収集、ツール利用、対話を通じた能動的なタスク遂行 |
| プロセス | 質問→検索→回答生成(直線的) | 質問→(思考・計画)→(検索・ツール利用・検証の反復)→回答生成(動的・反復的) |
| 情報収集 | 事前に定義されたデータベースからの検索が主 | 状況に応じて複数の情報源やツールを柔軟に活用 |
| 対応範囲 | 比較的単純な情報検索と要約が中心 | 複雑な質問、複数ステップを要するタスク、深い分析や推論 |
| 精度向上 | プロンプトエンジニアリングや検索DBの質に依存 | 自律的な検証や戦略的な情報収集により、よりロバストな精度向上が期待できる |
従来のRAGは、ユーザーが指示した通りに情報を検索し、提示された情報を基に回答を生成するという、どちらかと言えば「受動的」な仕組みでした。データベースの質や検索アルゴリズムの精度が回答の質を大きく左右します。
それに対しAgentic RAGは、LLM自身が「どのようにすれば最適な回答を導き出せるか」を考え、行動します。まるで人間が調査を行うように、複数のステップを踏み、試行錯誤を繰り返しながら、より質の高い情報を収集し、深い洞察に基づいた回答を生成しようとします。この「能動的」なアプローチが、Agentic RAGの最大の特徴であり、従来のRAGとの決定的な違いと言えるでしょう。
まとめ – Agentic RAGが拓く新たな可能性
Agentic RAGは、従来のRAGの課題であった、より複雑な質問への対応や、深い分析能力の限界を克服する可能性を秘めた技術です。LLMが単なる文章生成ツールから、自律的に思考し行動する「エージェント」へと進化することで、私たちの情報収集や問題解決の方法に大きな変革をもたらすかもしれません。
まだ発展途上の技術ではありますが、Agentic RAGが実用化されれば、より高度なリサーチ業務の自動化、複雑な意思決定支援、パーソナライズされた情報提供など、幅広い分野での活用が期待されます。今後の動向から目が離せません。