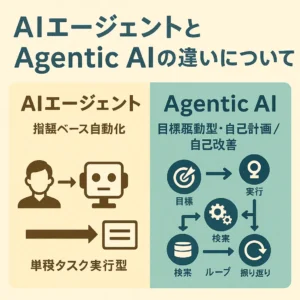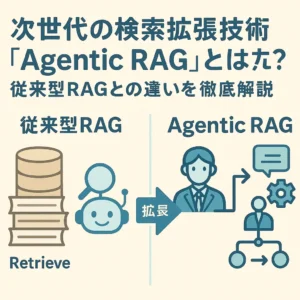
ここ数年で、私たちの働き方や情報の探し方に大きな変化をもたらしている生成AI。特に大規模言語モデル(LLM)は、まるで人間と対話しているかのような自然な文章を生成し、質問応答、文章要約、翻訳など、多岐にわたる分野で活躍しています。
しかし、そんなLLMにも苦手なことや課題が存在します。その課題を克服し、LLMの可能性をさらに広げる技術として注目されているのが「RAG(Retrieval-Augmented Generation)」です。
このコラムでは、「RAGって何?」「どうして必要なの?」といった疑問にお答えするべく、RAGの基本の「き」を分かりやすく解説します。
そもそもRAGとは?
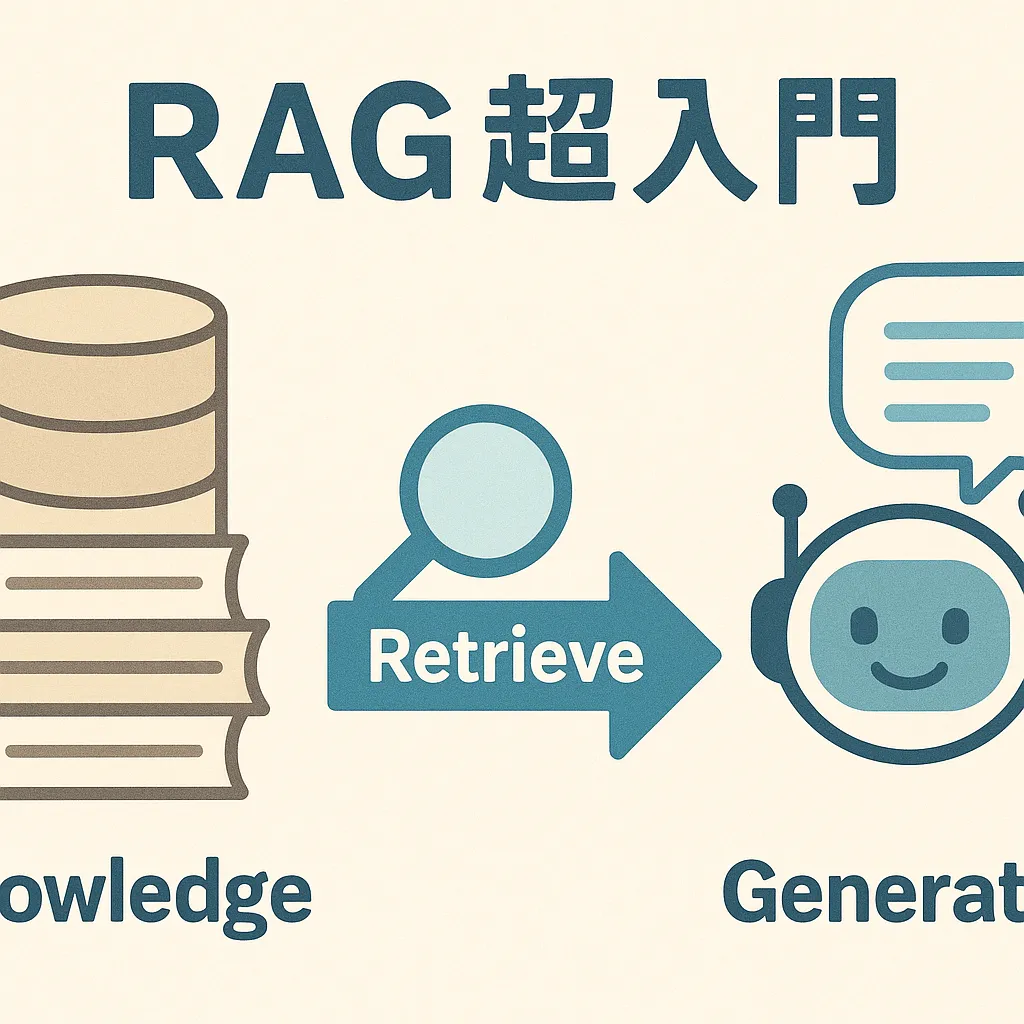
RAGとは、「Retrieval-Augmented Generation」の略で、日本語では「検索拡張生成」と訳されます。なんだか難しそうに聞こえるかもしれませんが、仕組みは意外とシンプルです。
一言でいうと、LLMが回答を生成する際に、あらかじめ用意された外部の知識データベースから関連情報を検索(Retrieval)し、その情報を参考にして回答を「拡張(Augmented)」して生成(Generation)する技術のことです。
例えるなら、試験で「教科書や参考書の持ち込みが許可された」状態を想像してみてください。LLMが学生だとすると、RAGは持ち込みが許可された教科書や参考書(外部の知識データベース)を使って、より正確で詳細な解答を作成するようなイメージです。
LLM単体でも膨大な知識を持っていますが、その知識は学習データに基づいているため、どうしても限界があります。RAGは、このLLMの「脳内」だけではカバーしきれない情報を、外部から補うことで、より賢く、より信頼できる回答を生み出すための仕組みなのです。
なぜ生まれた? LLMの課題を解決するために
RAGが登場した背景には、LLMが抱えるいくつかの課題があります。
- ハルシネーション(Hallucination): LLMは時として、事実に基づかない情報や、もっともらしい嘘を生成してしまうことがあります。これを「ハルシネーション」と呼びます。まるで自信満々に間違ったことを言っているようで、困ってしまいますよね。
- 知識のカットオフ(Knowledge Cutoff): LLMの知識は、学習に使われたデータセットが作成された時点までの情報に基づいています。そのため、それ以降の最新情報や出来事については基本的に答えることができません。「今日の天気は?」と聞いても、LLMが学習した最後の時点での「今日」の天気しか知らない、といった具合です。
- 専門性・社内情報への対応の難しさ: 一般的な知識には強いLLMですが、特定の業界の専門知識や、社内ルール、機密情報といったクローズドな情報については、当然ながら学習データに含まれていないため対応できません。
これらの課題を解決するために、「LLMに外部からカンニングペーパー(信頼できる情報源)を渡してあげよう!」という発想から生まれたのがRAGです。外部の最新かつ正確な情報を参照することで、上記の課題を軽減し、LLMの回答の質を向上させることが期待されています。
RAGのメリット:どんな嬉しいことがある?
RAGを導入することで、具体的にどのようなメリットがあるのでしょうか。
- ハルシネーションの抑制: 回答を生成する際に、根拠となる情報を外部から取得するため、LLMが事実に基づかない情報を生成するハルシネーションを大幅に減らすことができます。回答の信頼性が向上するのは大きなメリットです。
- 最新情報への対応: 外部の知識データベースを常に最新の状態に保つことで、LLMは最新の情報に基づいた回答を生成できるようになります。ニュース性の高い情報や、日々変化する製品情報などにも対応しやすくなります。
- 専門性・社内知識の活用: 特定の業界の専門文書や、社内マニュアル、過去の問い合わせ履歴などを知識データベースとしてRAGに連携させることで、その分野に特化した専門的な回答や、社内情報に基づいた応答が可能になります。これにより、顧客対応の高度化や業務効率化が期待できます。
- 透明性と説明可能性の向上: RAGは、回答を生成する際に参照した情報源を提示することができます。これにより、なぜそのような回答になったのか、その根拠は何か、といった透明性が高まり、ユーザーは回答をより信頼しやすくなります。
- LLMの再学習コストの削減: 新しい情報をLLMに反映させたい場合、通常はLLM自体を再学習(ファインチューニング)する必要がありますが、これには多くの時間とコストがかかります。RAGであれば、外部の知識データベースを更新するだけで済むため、より手軽かつ低コストで情報を最新化できます。
注意点・つまずきポイント:万能ではない?
多くのメリットがあるRAGですが、導入や運用にあたってはいくつかの注意点や、つまずきやすいポイントがあります。
- 検索品質の重要性: RAGの性能は、外部知識データベースからいかに的確な情報を検索できるかに大きく左右されます。「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」という言葉があるように、検索結果の質が低いと、当然ながら生成される回答の質も低下してしまいます。
- 知識ベースの構築と管理の手間: 質の高い知識ベースを準備し、それを常に最新の状態に保つためには、手間とコストがかかります。どのような情報を、どのような形式で、どの程度の粒度で知識ベースに格納するかが重要になります。
- プロンプトエンジニアリングの工夫: 検索してきた情報を、LLMにどのように効果的に伝え、望ましい回答を生成させるか、というプロンプト(指示文)の設計も重要です。適切な指示を与える工夫が求められます。
- システム全体の複雑性: RAGは、LLMに加えて検索システムや知識データベースといった複数のコンポーネントを連携させる必要があるため、システム全体の構成が複雑になりがちです。
- コスト: 知識データベースの構築・維持、検索システムの利用、そしてLLMのAPI利用料など、RAGシステムの運用には様々なコストが発生します。
- 評価の難しさ: RAGシステム全体の性能(検索の精度、生成される回答の質など)を客観的に評価し、改善していくことは簡単ではありません。あらかじめ評価指標を設計しておく必要があります。
おわりに
RAGは、LLMの可能性を大きく広げ、より実用的で信頼性の高いAIアシスタントを実現するための鍵となる技術です。ハルシネーションを抑え、最新情報や専門知識にも対応できるRAGは、今後ますます多くの分野での活用が期待されています。
もちろん、注意点や課題も存在しますが、それらを理解した上で適切に活用すれば、ビジネスや私たちの生活に大きな変革をもたらすポテンシャルを秘めています。
このコラムが、RAGという技術への理解を深める一助となれば幸いです。